WhereWithAll: A Personal Family Atlas
Turning eight years of adoption-discovery data — DNA matches, places, photos, memories — into a local, browsable family atlas, with a memory layer extracted by a local LLM for zero cost.
Since uncovering my adoption roots 8 years ago, I’ve slowly been discovering my genetic family and getting in touch with them. I met my birth mother for the first time in 2018 (via an ancestry.com DNA test), and just last year I met a paternal uncle (found via his daughter, my cousin on 23andMe) when he came out to Spain to meet me.
There are a few long stories behind the last 8 years of discovery. One involves my birth father, born in London at St Mary’s in Paddington. I moved from Indiana to London at 14, lived in Kensington & Chelsea, and must have walked past that hospital dozens of times. My uncle also brought footage of my great-grandfather, born in Hackney — another part of the city I know well. I spent 30-odd years kicking around various parts of London and Greater London, never knowing that I had British ancestry a couple generations back (as part of a longer story, I was led to believe from my adoption papers that my father was of Norwegian descent — but that’s something for another time).
But that proximity — undiscovered, uncrossed — is what pushed me to actually build something from all the data that I had at my disposal. I took all of my ancestry.com and 23andme.com data and poured it into a local repo I’ve called WhereWithAll: a personal universe of places, people, photos, and memory, centred on me.
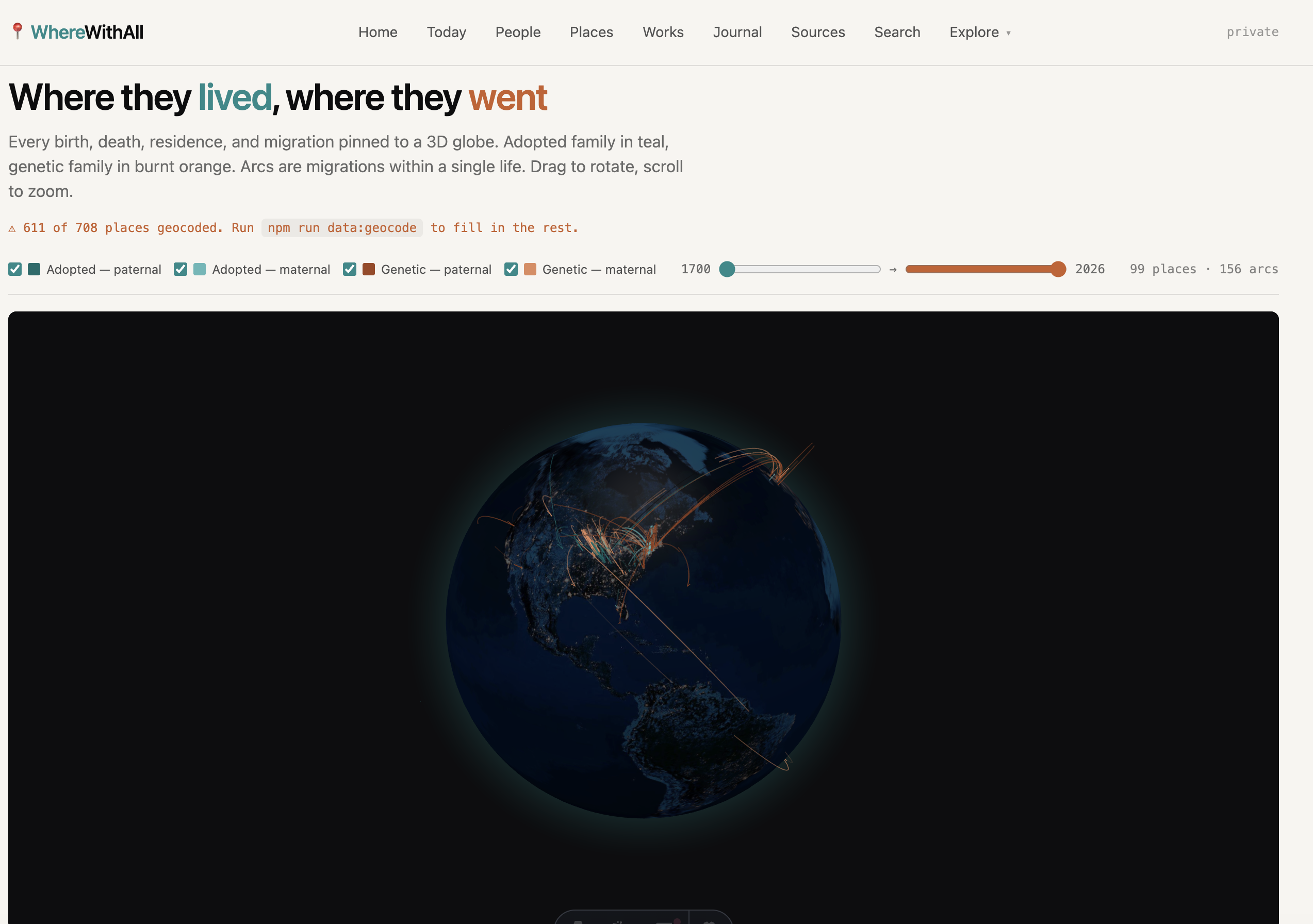
The current layer is OpenStreetMap data on each family member — place of birth, place of death, any other notable locations that have shown up in records or conversations. Where media exists, I’m linking it in. I’ve also been pulling location data from Apple Photos for notable experiences in my own life. The goal is a Family Atlas I can browse: journal entries, videos, family members plotted across the globe, showing where our paths have intersected — and where they nearly did.
To fill in the memory layer, I ran Ollama’s gemma4 against 603 candidate daily notes (filtered from 2,172) over 2h 14m of compute. It extracted 211 high and medium confidence cultural-memory entries with structured fields. Cost: zero. The same job on the Claude API would have been real money.
It’s staying local, but here’s a screenshot.